Memory-safe programming in the Linux Kernel (No not Rust) — eBPF.
By Jason Thomas
Here at CoScreen many of our engineers and staff are huge Linux enthusiasts. The backend of CoScreen is running on Linux, from our data analytics systems, presence and calling, to our video and backup infrastructure. One could easily say Linux is the real Wizard behind the curtain generating the CoScreen platform.
 |
Bringing CoScreen to Linux is high on our priority list, but due to the fragmentation of the Linux ecosystem, we will likely have to target very specific distributions of Linux, to begin with, and potentially provide a subset of functionality to certain distributions. We definitely will keep the community posted as we build in this direction, and feedback on what distributions would be the most effective to target for our community would be greatly appreciated.
That said, we have watched eagerly recent developments to introduce Rust into the Linux Kernel to make writing memory-safe drivers easier, and eliminate an entire class of memory-related security bugs: the Linux Rust patchset.

However, another very interesting and somewhat tangential development in the Linux kernel has been the introduction of eBPF (which has been around since 2014), which already provides a facility for loading fast memory-safe and sandboxed programs into the Linux Kernel. In fact, you can already compile and run Rust in the Linux kernel using eBPF: PoC: compiling to eBPF from Rust. I realize this isn’t entirely an apples-to-apples comparison, but the hyperbole got you to read this far didn’t it? So sit back, and enjoy the ride into exploring the exciting world of eBPF.
What is eBPF?
eBPF is a revolutionary technology that can run sandboxed programs in an operating system kernel. One of the exciting assurances of eBPF programs is that it guarantees that the programs loaded into the kernel cannot crash, and cannot run forever. eBPF is fascinating and unique in its scope and capability concerning its goal of providing system observability. It uses a very different approach when compared to other solutions in the Unix/BSD space such as OpenBSM (originated by Sun, and used in OSX), or previous solutions in the Linux space like the Linux audit framework. eBPF (as its name would imply) originated with Berkley Packet Filters (BPF introduced in 1992). Berkley Packet Filters were created originally mostly to analyze and customize network traffic in an efficient manner. BPF in itself is available on most major operating systems, including OSX, Windows, and Linux. The mechanism by which BPF works is what is most fascinating, in that it provides an in-kernel virtual machine most of which use a JIT compiler very much like modern interpreted environments like .NET/V8/JVM. eBPF, or extended BPF, is available on Linux (4.4+ kernels and 3.10+ RedHat back-ported) at the time this is being written, and is experimentally available on Windows.
eBPF programs can be compiled from a memory-safe subset of C using the BPF Compiler Collection (BCC). Writing eBPF code is a lot like writing any standard kernel-level code, in the sense that you are often reaching into kernel structures, and writing low-level C code to parse and make sense of them. The subset of C it provides and the verification stages it runs to ensure valid memory use or identify deadlocks or potentially endless loops is definitely challenging and fun to work with. I have found however that few problems can’t be solved or reasoned about without using indefinite loops, only statically allocated memory with fixed and known bounds, and a bit of creativity.
In fact, in 2019, I managed to write a mechanism that pulled the full path of an FD into kernel space by walking the dentry structure which I posted some details about here. Don’t be fooled by the loop, you can obviously use any loop that the compiler can automatically unroll. While this is evidence that there is still a great deal of work to be done with eBPF as a general tracing facility; the fact I managed to do this despite there not being official support for reverse lookup of an FD in eBPF yet is evidence of its extreme flexibility. The flexibility with which eBPF provides you basically leaves you in a situation where you are seldom painted into a corner by current limitations.
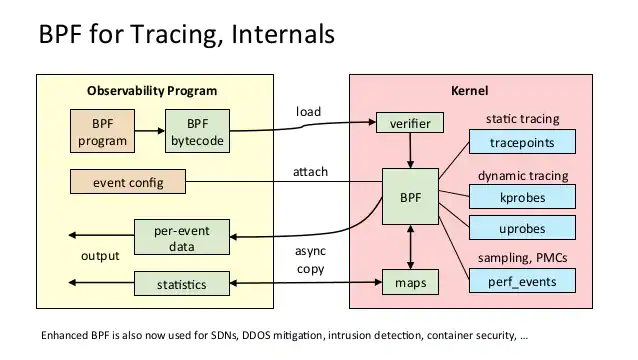
BPF tracing diagram from Brendan Gregg’s awesome blog.
This diagram gives a pretty decent overview of the general workflow of an eBPF program. You compile the bytecode against the running kernel, send it to the kernel where it runs through a verification stage, it has access to various resources, and data is then dispatched back to userspace to be processed.
How does it compare?
Most observability solutions are fixed in their scope. Data is collected very explicitly in syscall handlers internal to the kernel, in-memory structures are filled, and a userspace to kernel mechanism is used to pull that data to interested userspace observers.
OpenBSM defines a set of structures and a very efficient user-space polling mechanism. It has a well-optimized binary protocol, that provides a useful design and framework for building similar monitoring systems. It was designed originally by Sun for Solaris-based systems and is available on OSX. It is somewhat beleaguered by its history, in that there are traces for now completely outdated Solaris-specific operating system features, as well as very little documentation regarding what the precise meaning is of some of its traces. There are advantages to this interface, in that it’s already quite efficient, and it is extremely back-portable since it has a clearly defined interface. It’s also extremely complete in its implementation with regards to OSX, and there exists a trace for most low-level system calls related to networking, file operations, running executables, etc…
Audit in my opinion is much less complete, often loses traces due to its queue-based data storage mechanism that easily overflows, offers a user-space data retrieval mechanism that can only be used by one user-space process at a time, among other shortcomings that has caused it to fall out of favor on Linux.
eBPF takes a completely different approach, providing the ability to compile and load BPF bytecode from userspace, to insert completely custom programs, which have a low-level interface into the kernel to be able to set explicit tracepoints, hooks, and to manage and transmit data into and out of the kernel to userspace in a completely custom fashion. One could for instance build using eBPF an OpenBSM compatible tracing system from scratch without much trouble. In short, eBPF is much more comprehensive than any other observability solution, and opens up the possibility of doing things beyond just observability.
If you are looking for more in-depth details, there are some excellent resources, especially those from Brendan Gregg, who is a legend in the eBPF space, and who has written some excellent books on the subject.
Harsh limitations, but unlimited future possibilities.
For mission-critical tracing, and observability, obviously any trace that could catastrophically interact with your system and its performance is an absolute no-go, so it’s exciting to have something with the flexibility of eBPF, that comes with extremely strong safety and performance assurances. As mentioned earlier, eBPF does this by running a verification step on the loaded BFP bytecode in the kernel. At the moment eBPF programs cannot mutate or modify in-kernel data, only observe it. This paired with safe user-space modification of kernel state however can make some extremely powerful hybrid security and general-purpose drivers already. There is some talk about producing mechanisms to allow modification in the future through clean and well-defined interfaces similar to how BPF packet filters work for security purposes. There already exist several applications in conjunction with for instance systemd for using eBPF compiled programs for various types of filtering, accounting, and system control, or for instance with cilium for providing networking, load-balancing, and security to Kubernetes.
In fact, eBPF is so powerful, and some of these proposals will open up the capabilities of eBPF so much, many are beginning to suspect that eBPF is becoming a facility for Linux itself to become something akin to a microkernel. The ability to safely provide critical hot-patches without reloading or restarting the kernel, providing an interface of observability for process blocking, network filtering, and security, or even perhaps one day the ability to write and hot-load completely safe, verifiable, device drivers are just a few of the possibilities this would open up. Linux kernel modules already give some of this flexibility, as does the ability to hot-reload kernels, but the safety features, performance insurances, and sandboxing of eBPF programs take these capabilities into a completely new realm.
Every Linux user knows haphazardly removing and inserting modules is just asking for trouble; also the general safety and interaction with other modules for out-of-tree modules isn’t assured. Linux goes out of its way if there is a kernel panic to identify any out-of-tree modules so that customers will chase after vendors who produce them even if the fault has nothing to do with their module. eBPF is also starting to provide some answers with for instance BTF to age-old questions concerning stable driver interfaces or APIs. Drivers at the moment in Linux are pretty much useless if not compiled from source. Each module has a VERMAGIC string embedded in it, that the kernel will refuse to load even if there are no binary-level incompatibilities. The official position of kernel developers in the past is that requesting a stable kernel API is asking for “nonsense,” and that if developers want their drivers to be stable, they must provide them as source, and have them integrated into the main kernel tree.
This is a fair argument for vendors of for instance proprietary graphics drivers, who want to obfuscate or disable their hardware-level features, who benefit from the open-source ecosystem without providing back source that would be of general-interest to kernel developers and users. However, for vendors of for instance domain-specific security drivers that are not of general interest to kernel users, it’s a gigantic burden to overcome. Some commercial vendors have gone the route of using DKMS, which provides a mechanism for dynamically distributing drivers in a package that can be automatically recompiled, but also doesn’t work very well. Another strategy has been to simply build and package a module for literally every kernel version you could possibly conceive of or to patch VERMAGIC for drivers between versions without significant binary changes (which is incredibly unsafe). For many commercial developers, especially those in the security space, this has been a non-starter or forced them to support a small defined list of distributions. eBPF seems like a path out of this situation, that will allow a great deal of innovation and exploration, in a completely safe way, without hampering the kernel developers.
More details, and limitations.
One serious current limitation of eBPF is that programs have to be compiled with the correct kernel headers for the current configuration of the kernel where the program is being loaded, or have to be on a system that supports BTF. BCC provides an interface to dynamically compile, load, inject, and monitor an eBPF program. BCC can also be mostly statically compiled and linked via MUSL, allowing your eBPF program to be targeted and distributed across a host of Linux distributions and kernels. Combined with the ability to set and access Linux Tracepoints, which provide a much more generic and stable tracing mechanism than kprobes, a mechanism to fetch headers, it’s highly possible to both package and distribute eBPF services to customers and various environments using just BCC today.
I know eBPF can be portable because I built a general facility to compile and distribute headers for RedHat/Ubuntu/SUSE/CentOS and a BCC-based eBPF program for a cybersecurity company I previously worked for. The good news is Linux now supports CONFIG_IKHEADERS which will provide headers automatically that can be consumed by BCC via /sys/kernel/kheaders.tar.xz, but it may not be enabled or available on all distributions, and it’s likely CONFIG_DEBUG_INFO_BTF will become more common default in more distros in the future.
The eBPF community however is moving along at a brisk pace, and BTF, and CO-RE are paving the path to allowing kernels to have a truly compile-once run anywhere (hopefully better than Java applets) approach to deploying eBPF programs. Basically, BTF allows your eBPF program to dynamically be loaded against the current running kernel’s type information to determine the offsets to various kernel structures it makes use of. More details regarding BPF portability with CO-RE can be found here. The downside is that it requires that your kernel be compiled with CONFIG_DEBUG_INFO_BTF enabled, which few mainstream kernels currently have at the time of this article being written. For now, the truly cross-platform approach is using BCC and kernel headers, although it’s great to know it’s likely future Linux kernels and distributions will have a reduced-dependency runtime for eBPF programs.
Needless to say the possibilities and future of eBPF are extremely exciting. The adoption and experimentation by Microsoft provide some foreshadowing for a future potential cross-operating system standard. Rust in the kernel for producing drivers is extremely exciting too, but the micro-kernel, hot-patching, programming language-neutral future eBPF may provide to the kernel overshadows it by a long shot.
Getting Started
So how can you get started? You can find a pretty complete description of how to install BCC on your respective distribution and platform by reading the INSTALL document in the BCC repository. Many of their examples are Python-based, and there is a fairly complete array of various monitoring utilities and examples you can make use of.
But what if you want to make your own redistributable small eBPF utility that doesn’t require distribution-specific dependencies today?
One of the best tricks for making MUSL linked redistributable binaries is to use docker to make a static build targeting Alpine Linux (which is MUSL based), and then pull the resulting binaries out of that image. Unfortunately, it’s not this simple with BCC due to its use of dlopen internally. You can instead just statically link libc and libc++, as well as literally everything except for ld-musl-x86_64.so.1, which is the approach my quick start example, BCC from scratch, takes. If you’re deploying to an Alpine or MUSL based system, just check if deploy/lib/ld-musl-x86_64.so.1 already exists in /lib, and if it doesn’t deploy it there from the deployed bundle.
A lot of people are down on statically compiling binaries, for a multitude of reasons, but there are often reasons why small, redistributable binaries, are desirable. Go has proven out this model pretty well, building its entire runtime into its binaries, any only minimally linking dynamic dependencies from its environment, making Go binaries extremely portable (but often large). MUSL allows you to produce very similar reproducible, self-contained tools that you can easily deploy out to servers, infrastructure, and even to customers. But mostly it’s great to be able to just get started quickly and to deploy and start doing interesting things on your own infrastructure without worrying too much about how those systems are individually configured.
Ubuntu’s Linux header packages are great and usually up to date, and it’s pretty easy to target them, and on other distributions, if they support CONFIG_IKHEADERS it will be a breeze. Otherwise, you will need to make some effort to find and deploy matching headers in order for your eBPF program to be able to compile and insert itself into the kernel, which is a very distribution-specific, but solvable endeavor. In the future we will look into libbpf, BTF, and CO-RE, which should be able to accomplish the same thing in a much more minimal and portable fashion
Building BCC from scratch:
- First clone the project
git clone https://github.com/thedracle/bcc-from-scratch.git
Example:
- Then run the build script:
cd bcc-from-scratch
./bin/build.sh
- You will need to have docker installed on your system, and will have the best success on an Ubuntu 20.04 LTS system: https://docs.docker.com/engine/install/ubuntu/
Example:

❗ Note: Building on OSX (including the M1) has been tested, but not running via the Docker VM, this is unknown territory, so proceed with caution.
If you’re on an M1 Mac, you’ll want to change up the build command in build.sh to compile instead for x86 (unless you’re deploying to an ARM Linux target):
docker buildx build —platform --platform linux/amd64 .
To those bold folks who decide to go into the running on OSX wilderness anyways ⛵ bon voyage, and take this as a parting gift: https://petermalmgren.com/docker-mac-bpf-perf/
- Once you are finished you should have a deploy directory created with the build artifacts in it.
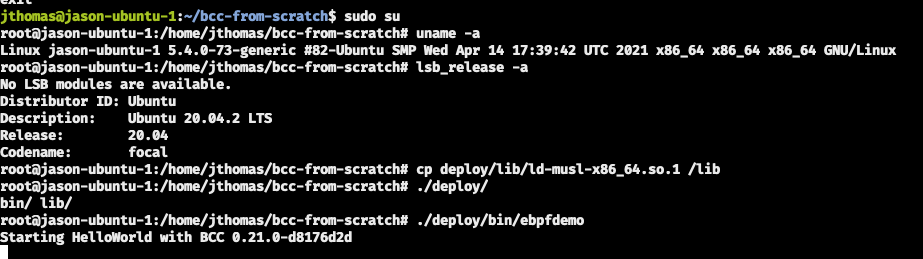
You will have to be root to run the sample, here is an example of running from the built deploy folder on a vanilla Ubuntu 20.04 LTS system:
sudo su
cd ./deploy/
./lib/ld-musl-x86_64.so.1 ./bin/ebpfdemo
❗ Or for those bold enough to want to patch their environment to run the binary:
cp ./deploy/lib/ld-musl-x86_64.so.1 /lib
./deploy/bin/ebpfdemo
Example:
⚠️ Common mistake ⚠️
If you run into a no such file or directory error output when running ebpfdemo, it means it wasn’t able to find the musl library, and you will have to find a way to get it into your library PATH.
🎉 Good luck and happy hacking with eBPF! 🎉